敏感词过滤算法
About 7 min
敏感词过滤算法
敏感词过滤,说白了就是字符串匹配,看输入的字符串是否存在敏感词。
常见的比较好的算法有KMP,Tire树,AC自动机(KMP+Trie)
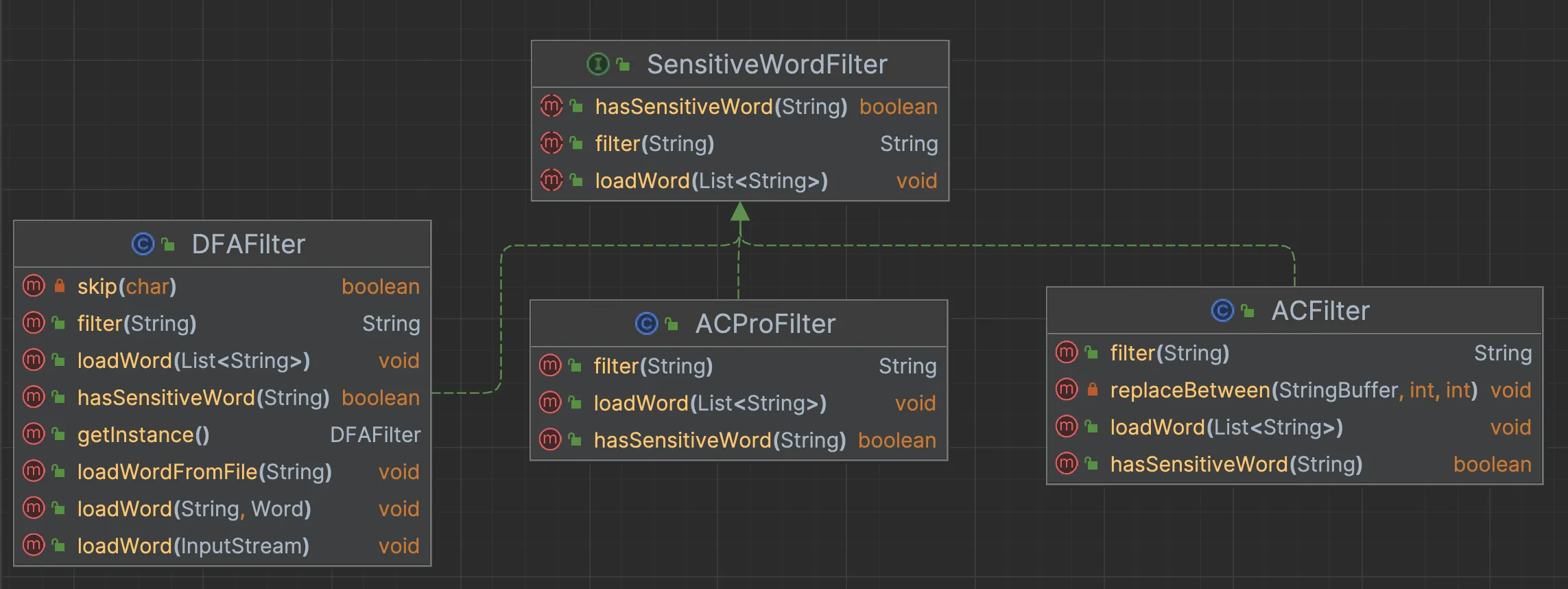
整体结构
我们定义SensitiveWordFilter接口,然后有不同算法的实现策略
三个核心功能,分别是过滤敏感词,判断是否命中敏感词,以及构建敏感词树。
敏感词过滤配置类
@Configuration
public class SensitiveWordConfig {
@Autowired
private MyWordFactory myWordFactory;
/**
* 初始化引导类
*
* @return 初始化引导类
* @since 1.0.0
*/
@Bean
public SensitiveWordBs sensitiveWordBs() {
return SensitiveWordBs.newInstance()
.filterStrategy(DFAFilter.getInstance())
.sensitiveWord(myWordFactory)
.init();
}
}
在filterStrategy(DFAFilter.getInstance())可以替换不同的策略
使用:
@Resource
private SensitiveWordBs sensitiveWordBs;
sensitiveWordBs.filter(body.getContent())
下面是算法的实现代码:
AC自动机
ACTrie
/**
* aho-corasick算法(又称AC自动机算法)
*/
@NotThreadSafe
public class ACTrie {
// 根节点
private ACTrieNode root;
public ACTrie(List<String> words) {
words = words.stream().distinct().collect(Collectors.toList()); // 去重
root = new ACTrieNode();
for (String word : words) {
addWord(word);
}
initFailover();
}
public void addWord(String word) {
ACTrieNode walkNode = root;
char[] chars = word.toCharArray();
for (int i = 0; i < word.length(); i++) {
walkNode.addChildrenIfAbsent(chars[i]);
walkNode = walkNode.childOf(chars[i]);
walkNode.setDepth(i + 1);
}
walkNode.setLeaf(true);
}
/**
* 初始化节点中的回退指针
*/
private void initFailover() {
// 第一层的fail指针指向root
Queue<ACTrieNode> queue = new LinkedList<>();
Map<Character, ACTrieNode> children = root.getChildren();
for (ACTrieNode node : children.values()) {
node.setFailover(root);
queue.offer(node);
}
// 构建剩余层数节点的fail指针,利用层次遍历
while (!queue.isEmpty()) {
ACTrieNode parentNode = queue.poll();
for (Map.Entry<Character, ACTrieNode> entry : parentNode.getChildren().entrySet()) {
ACTrieNode childNode = entry.getValue();
ACTrieNode failover = parentNode.getFailover();
// 在树中找到以childNode为结尾的字符串的最长前缀匹配,failover指向了这个最长前缀匹配的父节点
while (failover != null && (!failover.hasChild(entry.getKey()))) {
failover = failover.getFailover();
}
// 回溯到了root节点
if (failover == null) {
childNode.setFailover(root);
} else {
// 更新当前节点的回退指针
childNode.setFailover(failover.childOf(entry.getKey()));
}
queue.offer(childNode);
}
}
}
/**
* 查询句子中包含的敏感词的起始位置和结束位置
*
* @param text
*/
public List<MatchResult> matches(String text) {
List<MatchResult> result = Lists.newArrayList();
ACTrieNode walkNode = root;
for (int i = 0; i < text.length(); i++) {
char c = text.charAt(i);
while (!walkNode.hasChild(c) && walkNode.getFailover() != null) {
walkNode = walkNode.getFailover();
}
// 如果因为当前节点的孩子节点有这个字符,则将walkNode替换为下面的孩子节点
if (walkNode.hasChild(c)) {
walkNode = walkNode.childOf(c);
// 检索到了敏感词
if (walkNode.isLeaf()) {
result.add(new MatchResult(i - walkNode.getDepth() + 1, i + 1));
// 模式串回退到最长可匹配前缀位置并开启新一轮的匹配
// 这种回退方式将一个不漏的匹配到所有的敏感词,匹配结果的区间可能会有重叠的部分
walkNode = walkNode.getFailover();
}
}
}
return result;
}
}
ACTrieNode
@Getter
@Setter
public class ACTrieNode {
// 子节点
private Map<Character, ACTrieNode> children = Maps.newHashMap();
// 匹配过程中,如果模式串不匹配,模式串指针会回退到failover继续进行匹配
private ACTrieNode failover = null;
private int depth;
private boolean isLeaf = false;
public void addChildrenIfAbsent(char c) {
children.computeIfAbsent(c, (key) -> new ACTrieNode());
}
public ACTrieNode childOf(char c) {
return children.get(c);
}
public boolean hasChild(char c) {
return children.containsKey(c);
}
@Override
public String toString() {
return "ACTrieNode{" + "failover=" + failover + ", depth=" + depth + ", isLeaf=" + isLeaf + '}';
}
}
ACFilter
/**
* 基于ac自动机实现的敏感词过滤工具类
* 可以用来替代{@link ConcurrentHistogram}
* 为了兼容提供了相同的api接口 {@code hasSensitiveWord}
*/
public class ACFilter implements SensitiveWordFilter {
private final static char mask_char = '*'; // 替代字符
private static ACTrie ac_trie = null;
/**
* 有敏感词
*
* @param text 文本
* @return boolean
*/
public boolean hasSensitiveWord(String text) {
if (StringUtils.isBlank(text)) return false;
return !Objects.equals(filter(text), text);
}
/**
* 敏感词替换
*
* @param text 待替换文本
* @return 替换后的文本
*/
public String filter(String text) {
if (StringUtils.isBlank(text)) return text;
List<MatchResult> matchResults = ac_trie.matches(text);
StringBuffer result = new StringBuffer(text);
// matchResults是按照startIndex排序的,因此可以通过不断更新endIndex最大值的方式算出尚未被替代部分
int endIndex = 0;
for (MatchResult matchResult : matchResults) {
endIndex = Math.max(endIndex, matchResult.getEndIndex());
replaceBetween(result, matchResult.getStartIndex(), endIndex);
}
return result.toString();
}
private static void replaceBetween(StringBuffer buffer, int startIndex, int endIndex) {
for (int i = startIndex; i < endIndex; i++) {
buffer.setCharAt(i, mask_char);
}
}
/**
* 加载敏感词列表
*
* @param words 敏感词数组
*/
public void loadWord(List<String> words) {
if (words == null) return;
ac_trie = new ACTrie(words);
}
}
AC-PRO
ACProTrie
public class ACProTrie {
private final static char MASK = '*'; // 替代字符
private Word root;
// 节点
static class Word {
// 判断是否是敏感词结尾
boolean end = false;
// 失败回调节点/状态
Word failOver = null;
// 记录字符偏移
int depth = 0;
// 下个自动机状态
Map<Character, Word> next = new HashMap<>();
public boolean hasChild(char c) {
return next.containsKey(c);
}
}
// 构建ACTrie
public void createACTrie(List<String> list) {
Word currentNode = new Word();
root = currentNode;
for (String key : list) {
currentNode = root;
for (int j = 0; j < key.length(); j++) {
if (currentNode.next != null && currentNode.next.containsKey(key.charAt(j))) {
currentNode = currentNode.next.get(key.charAt(j));
// 防止乱序输入改变end,比如da,dadac,dadac先进入,第二个a为false,da进入后把a设置为true
// 这样结果就是a是end,c也是end
if (j == key.length() - 1) {
currentNode.end = true;
}
} else {
Word map = new Word();
if (j == key.length() - 1) {
map.end = true;
}
currentNode.next.put(key.charAt(j), map);
currentNode = map;
}
currentNode.depth = j + 1;
}
}
initFailOver();
}
// 初始化匹配失败回调节点/状态
public void initFailOver() {
Queue<Word> queue = new LinkedList<>();
Map<Character, Word> children = root.next;
for (Word node : children.values()) {
node.failOver = root;
queue.offer(node);
}
while (!queue.isEmpty()) {
Word parentNode = queue.poll();
for (Map.Entry<Character, Word> entry : parentNode.next.entrySet()) {
Word childNode = entry.getValue();
Word failOver = parentNode.failOver;
while (failOver != null && (!failOver.next.containsKey(entry.getKey()))) {
failOver = failOver.failOver;
}
if (failOver == null) {
childNode.failOver = root;
} else {
childNode.failOver = failOver.next.get(entry.getKey());
}
queue.offer(childNode);
}
}
}
// 匹配
public String match(String matchWord) {
Word walkNode = root;
char[] wordArray = matchWord.toCharArray();
for (int i = 0; i < wordArray.length; i++) {
// 失败"回溯"
while (!walkNode.hasChild(wordArray[i]) && walkNode.failOver != null) {
walkNode = walkNode.failOver;
}
if (walkNode.hasChild(wordArray[i])) {
walkNode = walkNode.next.get(wordArray[i]);
if (walkNode.end) {
// sentinelA和sentinelB作为哨兵节点,去后面探测是否仍存在end
Word sentinelA = walkNode; // 记录当前节点
Word sentinelB = walkNode; // 记录end节点
int k = i + 1;
boolean flag = false;
// 判断end是不是最终end即敏感词是否存在包含关系(abc,abcd)
while (k < wordArray.length && sentinelA.hasChild(wordArray[k])) {
sentinelA = sentinelA.next.get(wordArray[k]);
k++;
if (sentinelA.end) {
sentinelB = sentinelA;
flag = true;
}
}
// 根据结果去替换*
// 计算替换长度
int len = flag ? sentinelB.depth : walkNode.depth;
while (len > 0) {
len--;
int index = flag ? i - walkNode.depth + 1 + len : i - len;
wordArray[index] = MASK;
}
// 更新i
i += flag ? sentinelB.depth : 0;
// 更新node
walkNode = flag ? sentinelB.failOver : walkNode.failOver;
}
}
}
return new String(wordArray);
}
}
ACProFilter
/**
*@description: 基于ACFilter的优化增强版本
*/
public class ACProFilter implements SensitiveWordFilter{
private ACProTrie acProTrie;
@Override
public boolean hasSensitiveWord(String text) {
if(StringUtils.isBlank(text)) return false;
return !Objects.equals(filter(text),text);
}
@Override
public String filter(String text) {
return acProTrie.match(text);
}
@Override
public void loadWord(List<String> words) {
if (words == null) return;
acProTrie = new ACProTrie();
acProTrie.createACTrie(words);
}
}
DFA
/**
* 敏感词工具类
*/
public final class DFAFilter implements SensitiveWordFilter {
private DFAFilter() {
}
private static Word root = new Word(' '); // 敏感词字典的根节点
private final static char replace = '*'; // 替代字符
private final static String skipChars = " !*-+_=,,.@;:;:。、??()()【】[]《》<>“”\"‘’"; // 遇到这些字符就会跳过
private final static Set<Character> skipSet = new HashSet<>(); // 遇到这些字符就会跳过
static {
for (char c : skipChars.toCharArray()) {
skipSet.add(c);
}
}
public static DFAFilter getInstance() {
return new DFAFilter();
}
/**
* 判断文本中是否存在敏感词
*
* @param text 文本
* @return true: 存在敏感词, false: 不存在敏感词
*/
public boolean hasSensitiveWord(String text) {
if (StringUtils.isBlank(text)) return false;
return !Objects.equals(filter(text), text);
}
/**
* 敏感词替换
*
* @param text 待替换文本
* @return 替换后的文本
*/
public String filter(String text) {
StringBuilder result = new StringBuilder(text);
int index = 0;
while (index < result.length()) {
char c = result.charAt(index);
if (skip(c)) {
index++;
continue;
}
Word word = root;
int start = index;
boolean found = false;
for (int i = index; i < result.length(); i++) {
c = result.charAt(i);
if (skip(c)) {
continue;
}
if (c >= 'A' && c <= 'Z') {
c += 32;
}
word = word.next.get(c);
if (word == null) {
break;
}
if (word.end) {
found = true;
for (int j = start; j <= i; j++) {
result.setCharAt(j, replace);
}
index = i;
}
}
if (!found) {
index++;
}
}
return result.toString();
}
/**
* 加载敏感词列表
*
* @param words 敏感词数组
*/
public void loadWord(List<String> words) {
if (!CollectionUtils.isEmpty(words)) {
Word newRoot = new Word(' ');
words.forEach(word -> loadWord(word, newRoot));
root = newRoot;
}
}
/**
* 加载敏感词
*
* @param word 词
*/
public void loadWord(String word, Word root) {
if (StringUtils.isBlank(word)) {
return;
}
Word current = root;
for (int i = 0; i < word.length(); i++) {
char c = word.charAt(i);
// 如果是大写字母, 转换为小写
if (c >= 'A' && c <= 'Z') {
c += 32;
}
if (skip(c)) {
continue;
}
Word next = current.next.get(c);
if (next == null) {
next = new Word(c);
current.next.put(c, next);
}
current = next;
}
current.end = true;
}
/**
* 从文本文件中加载敏感词列表
*
* @param path 文本文件的绝对路径
*/
public void loadWordFromFile(String path) {
try (InputStream inputStream = Files.newInputStream(Paths.get(path))) {
loadWord(inputStream);
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 从流中加载敏感词列表
*
* @param inputStream 文本文件输入流
* @throws IOException IO异常
*/
public void loadWord(InputStream inputStream) throws IOException {
try (BufferedReader reader = new BufferedReader(new InputStreamReader(inputStream, StandardCharsets.UTF_8))) {
String line;
ArrayList<String> list = new ArrayList<>();
while ((line = reader.readLine()) != null) {
list.add(line);
}
loadWord(list);
}
}
/**
* 判断是否需要跳过当前字符
*
* @param c 待检测字符
* @return true: 需要跳过, false: 不需要跳过
*/
private boolean skip(char c) {
return skipSet.contains(c);
}
/**
* 敏感词类
*/
private static class Word {
// 当前字符
private final char c;
// 结束标识
private boolean end;
// 下一层级的敏感词字典
private Map<Character, Word> next;
public Word(char c) {
this.c = c;
this.next = new HashMap<>();
}
}
}